Hadoop介绍
Hadoop概述
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,是一个便于用户编写和运行大数据处理程序的软件框架。用户可以在不了解分布式底层细节的情况下,充分利用集群的威力高速存储和运算,开发分布式程序。Hadoop主要解决两个问题:海量数据的存储和海量数据的分析,对应包含两个核心部分:
分布式文件系统(HDFS)
HDFS是Hadoop Distributed File System的简称,是一个分布式文件系统。它适合部署在廉价的机器上,有着高容错性的特点,提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,实现流式读取文件系统数据,从而适用于批量数据的处理。HDFS开始是为开源的Apache项目nutch的基础结构而创建,现在是Hadoop项目的核心部分之一。
MapReduce
MapReduce是一种分布式编程模型,它允许用户在不了解分布系统底层细节的情况下开发并行应用程序,进行大规模数据集(PB级)的并行运算。一句话解释MapReduce就是“任务的分解与结果的汇总”。”Map(映射)”和”Reduce(化简)”以及他们的主要思想,都是从函数式编程语言和矢量编程语言里借来的。他极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。当前软件实现过程是:指定一个Map(映射)函数,用来把一组键值对形如(key, value),映射成一组新的键值对(key’, value’),指定并发的Reduce(化简)函数,用来保证所有映射的键值对中的每一个共享相同的键组。用户可以利用Hadoop轻松地组织计算机资源,搭建自己的分布式计算平台,并且可以充分利用集群的计算和存储能力,完成海量数据的处理,Hadoop主要有以下几个优点:
- 高扩展性:Hadoop是在可用的计算机集群间分配数据并完成计算任务的,集群可以方便地扩展到数以千计的节点中。
- 高容错性:Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
- 高效性:Hadoop能够在节点之间动态地移动计算,并保证各个节点的动态平衡,因此处理速度非常快。通过分布数据,Hadoop可以在节点上并行处理数据。存储和处理的数据达到PB(1024TB)级规模。
- 经济性:Hadoop将数据和处理过程分布到在普通的常用电脑上,组成集群,集群节点个数达数千个(以千为单位),同时,Hadoop是开源的,项目的软件成本因此会大大降低。
起源和发展
Hadoop最早起源于Nutch。Nutch是一个开源的网络搜索引擎,Doug Cutting于2002年创建。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等 功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题,即不能解决数十亿网页的存储和索引问题。之后,谷歌发表的两篇论文为该问题提供了可行的解决方案。一篇是2003年发表的关于谷歌分布式文件系统(GFS)的论文。该论文描述了谷歌搜索引擎网页相关数据的存储架构,该架构可解决Nutch遇到的网页抓取和索引过程中产生的超大文件存储需求的问题。但由于谷歌仅开源了思想而未开源代码,Nutch项目组便根据论文完成了一个开源实现,即Nutch的分布式文件系统(HDFS)。另一篇是2004年发表的关于谷歌分布式计算框架MapReduce的论文。该论文描述了谷歌内部最重要的分布式计算框架MapReduce的设计艺术,该框架可用于处理海量网页的索引问题。同样,由于谷歌未开源代码,Nutch的开发人员完成了一个开源实现。并将它与HDFS结合,用以支持Nutch引擎的主要算法。由于HDFS和MapReduce在Nutch引擎中的良好的应用,所以2006年初,开发人员便将其移出Nutch,成为Lucene的一个完整而且独立的子项目,称为Hadoop。2008年1月,Hadoop成为Apache顶级项目,迎来了它的快速发展期。
Hadoop这个名字不是一个缩写,它是一个虚构的名字。该项目的创建者,Doug Cutting如此解释Hadoop的得名:“这个名字是我孩子给一头吃饱了的棕黄色大象命名的。我的命名标准就是简短,容易发音和拼写,没有太多的意义,并且不会被用于别处。小孩子是这方面的高手。Google就是由小孩命名的。”
Hadoop及其子项目和后继模块所使用的名字往往也与其功能不相关,经常用一头大象或其他动物主题(例如:”Pig”)较小的各个组成部分给与更多描述性(因此也更俗)的名称。这是一个很好的原则,因为它意味着可以大致从其名字猜测其功能,例如,jobtracker的任务就是跟踪MapReduce作业。
下面是Hadoop大记事:
- 2013年2月:Wandisco推出了世界第一款可用于实际业务环境的Apache Hadoop 2 -WANdisco Distro(WDD)。
- 2011年12月27日:1.0.0版本释出,它标志着Hadoop已经初具生产规模。
- 2009年4月:赢得每分钟排序,59秒内排序500GB(在1400个节点上)和173分钟内排序100TB数据(在3400个节点上)。
- 2009年3月:17个集群总共24000台机器。
- 2008年10月:研究集群每天装载10 TB的数据。
- 2008年4月:赢得世界最快1TB数据排序在900个节点上用时209秒。
- 2007年4月:研究集群达到两个1000个节点的集群。
- 2007年1月:研究集群到达900个节点。
- 2006年12月:标准排序在20个节点上运行1.8个小时,100个节点3.3小时,500个节点5.2小时,900个节点7.8个小时。
- 2006年11月:研究集群增加到600个节点。
- 2006年5月:标准排序在500个节点上运行42个小时(硬件配置比4月的更好)。
- 2006年5月:雅虎建立了一个300个节点的Hadoop研究集群。
- 2006年4月:标准排序(10 GB每个节点)在188个节点上运行47.9个小时。
- 2006年2月:雅虎的网格计算团队采用Hadoop。
- 2006年2月:Apache Hadoop项目正式启动以支持MapReduce和HDFS的独立发展。
- 2006年1月:Doug Cutting加入雅虎。
- 2005年12月:Nutch移植到新的框架,Hadoop在20个节点上稳定运行。
- 2004年:最初的版本(现在称为HDFS和MapReduce)由Doug Cutting和Mike Cafarella开始实施。
Hadoop应用领域
对于Hadoop的应用,主要集中应用在如下方面:
- 数据挖掘与商业智能,包括日志处理,点击流分析,相似性分析,精准广告投放
- 数据仓库,特别是使用Pig和Hive。
- 生物信息技术(基因分析)。
- 金融模拟(例如,蒙特卡洛模拟)。
- 文件处理(例如,jpeg大小改修)。
- web索引。
- 日志分析
- 排序
Hadoop生态圈
简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台,其生态圈部分主要组成如下:
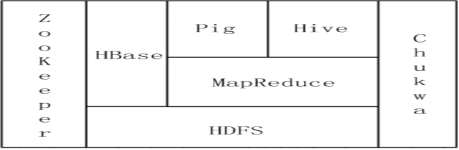
图1 Hadoop生态圈主要组成
- HDFS:分布式文件系统,运行于大型商用机集群。
- MapReduce:分布式数据处理模型和执行环境,运行于大型商用机集群。
- HBase:一个分布式、按列存储数据库,使用HDFS作为底层存储,同时支持MapReduce的批量式计算和点查询(随机读取)。
- Hive:一个分布式、按列存储的数据仓库,管理HDFS中存储的数据,并提供基于SQL的查询语言(由运行时引起翻译成MapReduce作业)用以查询数据。
- Pig:一种数据流语言和运行环境,用以检索非常大的数据集,运行在MapReduce和HDFS的集群上。
- Chukwa:简单的说,Chukwa基于Hadoop的大集群监控系统,可以用他来分析和收集系统中的数据(日志)。
- ZooKeeper:一个分布式、可用性高的协调服务,提供分布式锁之类的基本服务用于构建分布式应用。