Hadoop分布式集群环境的搭建
目的
- 了解Hadoop版本;
- 掌握Hadoop在伪分布式环境下的部署;
- 掌握Hadoop在集群环境下的部署;
准备
准备好三台计算机,安装好Ubuntu12.04 LS操作系统;熟悉Linux基本操作命令;实 验中要用到的工具和软件可在实验附属的文件中找到。
了解Hadoop的不同版本
Hadoop是一个开源的分布式处理的软件框架,包括多个子项目,最为主要的是HDFS和MapReduce,到目前为止已经有多个发行版本,下表给出了几个代表性的Hadoop版本的比较:
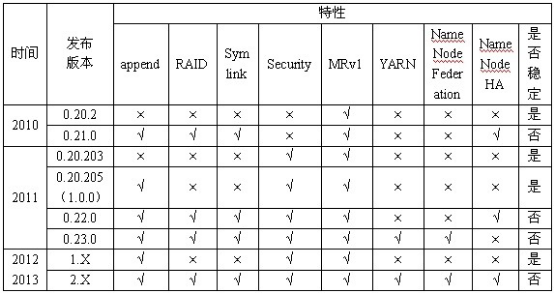
本实验中,我们选择Hadoop1.2.1版本,它是一个稳点的版本,其安装文件可以到http://hadoop.apache.org/releaseshtml#Download下载,也可以在实验附录的工具文件中找到Hadoop-1.2.1.tar.gz,所有的安装部署基于Ubuntu12.04操作系统,请在实验前自行安装好系统,并获得root权限。
Hadoop伪分布式环境搭建
Hadoop是运行在分布式集群中,利用集群的多节点并行处理大型数据计算;如果在单机环境下,也可以一窥Hadoop在并行计算中强大之处。所谓伪分布式,就是在单机环境下,在JVM中启动多个进程来模拟集群的多个节点,原来节点间的通信则简化为进程间的通信,但伪分布式模式仅供模拟与测试,在实际的开发中是不适用的。本实验由学习伪分布式环境搭建开始,在到完全的分布式集群,完全分布式集群环境的搭建有很多环节是与伪分布式相类似。
步骤一:创建Hadoop用户和用户组
在Ubuntu系统下创建新的用户和用户组,必须拥有root权限,而Ubuntu安装完成后root用户默认是不启用的,使用一下命令启用root,并设置root密码,设置root密码命令如下:
sudo passwd root
将会提醒你输入两次root密码,前一次是需要设置的root密码,第二是次重复确认。如果之前有开启并设置过root密码,则无需重复再设置。当获取root权限后,切换到root用户,使用以下命令创建新的用户和用户组:
su root
addgroup hadoop
adduser -ingroup hadoop hadoopuser
将添加hadoop用户组和hadoopuser用户,同时将用户hadoopuser添加到hadoop用户组中。修改/etc/sudoers文件,使hadoopuser用户具有执行root权限:
vim /etc/sudoers
#添加如下内容:
#user privilege specification
root ALL=(ALL:ALL) ALL
hadoopuser ALL=(ALL:ALL) ALL
步骤二:安装JDK
Hadoop是采用java语言开发的,需要在java虚拟机上运行,需要安装JDK,如果在安装Ubuntu时勾选了安装第三方软件,那么此时Ubuntu系统下已安装了JDK,可以使用java -version命令查看jdk版本;
java -version
Ubuntu系统一般默认安装OpenJDK,可能会对但hadoop的安装带来不必要的麻烦,所以一般采用SunJDK使用以下命令卸载OpenJDK。本实验工具包里有Oracle的sunJDK1.6压缩文件,在root用户下拷贝此文件至/usr/lib/jvm,先修改权限,后执行:
chmod -755 jdk-6u24-linux-i586.bin
./jdk-6u24-linux-i586.bin
mv jdk-1.6.1_24 jdk
本实验将JDK安装在/usr/lib/jvm目录下,因此安装完成后应该配置java相关的环境变量,Ubuntu系统下有多个地方可以修改环境变量,按系统加载顺序来说,主要是以下几个文件:
1)/etc/profile:在登录时,操作系统定制用户环境时使用的第一个文件,此文件为系统的每个用户设置环境信息,当用户第一次登录时,该文件被执行。
2)/etc/environment:在登录时操作系统使用的第二个文件,系统在读取你自己的profile前,设置环境文件的环境变量。
3)~/.profile:在登录时用到的第三个文件是.profile文件,每个用户都可使用该文件输入专用于自己使用的shell信息,当用户登录时,该 文件仅仅执行一次。默认情况下,它设置一些环境变量,执行用户的.bashrc文件。
4)/etc/bashrc:为每一个运行bash shell的用户执行此文件。当bash shell被打开时,该文件被读取。
5)~/.bashrc:该文件包含专用于你的bash shell的bash信息,当登录时以及每次打开新的shell窗口时,该文件被读取。
了解这些环境变量文件的作用之后,就可以设置java相关的环境变量,因为为了使java可以被多个用户使用,所以本实验在/etc/profile中设置JAVA_HOME,具体如下:
vim /etc/profile
#添加如下内容
#配置JAVA_HOME和PATH路径
export JAVA_HOME=”/usr/lib/jvm/jdk”
export PATH=”$PATH:$JAVA_HOME/bin”
#保存退出后,命令行执行:
source /etc/proflie
java -version
最后可以在任意目录下执行java -version命令查看JDK和环境变量是否正确配置,一定要确保JDK安装成功。
步骤三:配置SSH无密码登录
SSH(Secure Shell,安全壳协议)是远程登录和网络服务安全协议,提供两种身份验证:基于口令的安全验证和基于密钥的安全验证。
练习1:查阅资料,了解SSH相关内容和使用。
Hadoop集群中使用SSH协议使得主从节点之间能够相互通信,并且SSH被大多数Unix平台所支持。本实验使用基于密钥的安全验证,具体操作如下:在hadoopuser用户下,执行如下命令,生成本机SSH登录的公钥和密钥,
#命令行执行,全部选择回车默认
ssh-keygen -t rsa -P ''
默认情况下,生成的公私钥保存在用户主文件夹下的.ssh/目录中,上述命令返回后,会在~/.ssh目录下生成两个文件:id_rsa 和id_rsa.pub,在.ssh/目录下新建authorized_keys文件,将上面生成的公钥追加到此文件中,执行命令如下:
cat id_rsa.pub >> authorized_keys
authorized_keys文件保存了所有可以无密码登录本机或像本机发送消息的主机的公钥,如果B主机上有A主机的公钥,则B主机就可以无密码登录到A主机,上述操作中,将本机的公钥追加到authorized_keys,就表示本机可以无密码登录到本机(localhost),尝试以下操作:
ssh localhost
可以看到,如果可以本地SSH登录到localhost主机,则表示伪分布式下的SSH协议已经部署好,分布式集群环境下的SSH部署会略有不同,后面会讲到。
步骤四:安装Hadoop,配置Hadoop配置文件
本实验将Hadoop安装在hadoopuser用户主目录下,在/home目录下应该就有hadoopuser用户的主目录了,进入该目录,并将安装文件hadoop-1.2.1.tar.gz复制到此目录,使用tar命令解压,执行命令如下:
tar -zxvf ~/hadoop-1.2.1.tar.gz
解压后的文件就是Hadoop的主文件了,上述过程注意一定要在hadoopuser用户下执行;需要配置的Hadoop-1.2.1.版本的Hadoop配置文件主要有三个,并且都在HADOOP_HOME/conf文件目录下,分别为:
- core-site.xml
- hdfs-site.xml
- mpared-site.xml
下面分别阐述这几个配置文件的配置方法和含义;
1)配置core-site.xml文件
<configuration>
<property>
<name>fs.defalut.name</name>
<value>hdfs://localhost:9000</value>
<description></description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoopuser/hdfs/tmp</value>
<description></description>
</property>
</configuration>
上述配置文件中的第一个属性配置了HDFS文件系统中NameNode的URI,这里包括三部分,分别为:协议,主机名,端口号,这个URI其实是设置HDFS中所有文件访问URI的前缀,对于HDFS文件系统,课程讲义中有具体讲述,请自行查阅;在这里配置这个属性,是为了让集群中每一个节点都能够知道NameNode节点的位置;第二个属性hadoop.tmp.dir设置了文件系统依赖的基础配置目录,如果不配置此选项,会默认将/tmp路径作为此项的值;
2)配置hdfs-site.xml文件
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/home/hadoopuser/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoopuser/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
首先,dfs.name.dir选项配置了namenode上存储的hdfs文件系统信息在本地的存储路径,如果当前节点是DataNode,dfs.data.dir选项则配置了datanode上hdfs文件系统信息的本地存储路径,如果不配置这两项,那么这两项的值默认为core-site.xml文件中配置hadoop.tmp.dir选项的值。dfs.replaction选项配置了文件系统中文件块的备份数,配置为3表示一个文件块会有两个备份,当然,如果是伪分布式,不想占用太多的磁盘空间,可以将其设置为1。
练习2:思考,如果在core-site.xml和hdfs-site.xml中不配置hadoop.tmp.dir,dfs.name.dir和dfs.data.dir选项,会带来什么问题?
3)配置mapred-site.xml文件
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration> 在这个文件中配置了mapreduce作业的相关属性,mapred.job.tracker选项配置了MapReduce中jobTracker所在的节点的端口。
注:如果没有配置JAVA_HOME环境变量,则需要在hadoop-env.sh中进行配置;
4)配置masters和slaves文件
最后,在伪分布式环境下,配置masters和slaves文件,值都为localhost;
步骤五:添加Hadoop环境变量,格式化文件系统,并启动
上述配置文件修改完成后,伪分布式环境搭建的基本工作也差不多完成了,最后,为了方便操作,配置Hadoop相关的环境变量;
因为本实验搭建的Hadoop环境仅供hadoopuser用户使用,所以只需在~/.bashrc中添加Hadoop的PATH环境变量,如下:
vim ~/.bashrc
#打开.bashrc文件后,添加以下内容
export PATH=”$PATH:/home/hadoopuser/hadoop-1.2.1/bin”
需要注意的是,.bashrc文件的内容在重新开启一个shell时加载,所以必须先关闭当前修改.bashrc文件的窗口,重新开启一个命令窗口,查看环境变量是否正确设置。 完成添加后,可以在hadoopuser的任意目录下执行hadoop命令,系统会列出hadoop命令的一些帮助信息。命令输出结果应如下图所示:
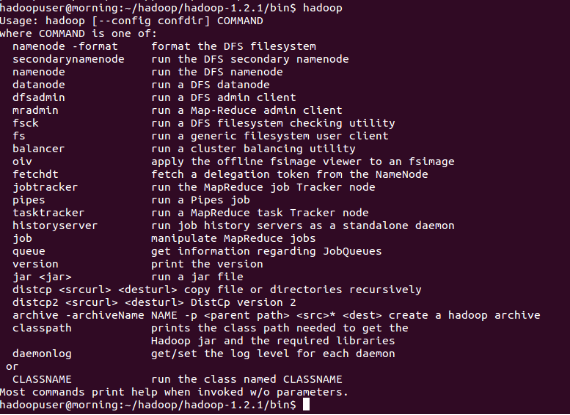
表明hadoop环境变量已经设置成功,接下来就可以在伪分布式环境下运行Hadoop了,作为第一次启动,首先需要格式化文件系统,使用命令: #hadoop用户执行,格式化DFS文件系统
hadoop namenode -format
格式化命令成功返回后,运行start-all.sh,启动Hadoop相关进程,由于是伪分布式,会在本机localhost上启动多个进程,执行jps命令,查看启动的进程:
#启动hadoop守护进程
start-all.sh
#查看hadoop相关进程是否正常启动
jps
命令输出结果应如图所示:
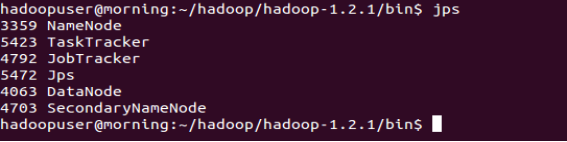
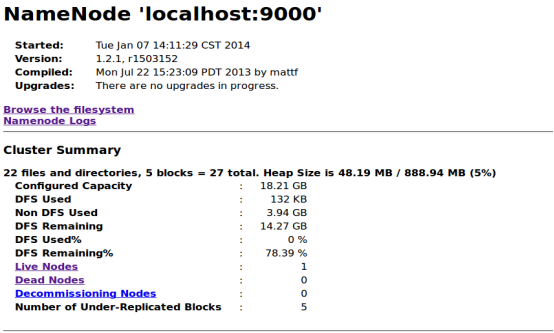
如果图中的进程全部启动,那么伪分布式Hadoop就启动完成了,可以在浏览器中键入localhost:50030或localhost:50070,查看启动后的Hadoop。
1)在浏览器中键入localhost:50030,可以看到下图结果

2)在浏览器中键入localhost:50070,可以看到下图结果
Hadoop集群环境下的部署
集群的部署环节大致与伪分布式相同,但由于节点是集群中的不同主机,所以在配置不同节点间的通信时会有一些与伪分布式不同,并值得注意的地方。
步骤一:创建Hadoop用户和用户组
单个节点的过程同伪分布式模式,不同的是必须在集群的每个节点上重复相同的操作;要注意的是,每个节点上必须使用相同的用户名(如:hadoopuser)和用户组名(如:hadoop)。
步骤二:安装JDK
过程同伪分布式模式下安装JDK,不同的是完全分布式集群下是在集群的每个节点中都需要安装JDK,和配置java环境。
步骤三:在集群中实现每个节点SSH无密码通信
这是与伪分布式最为不同的一点,在伪分布式下,所有的守护进程都在localhost节点上,即localhost既是NameNode,也是DataNode,既是JobTracker亦是TaskTracker,localhsot上利用不同的进程来模拟多节点环境,在真正的集群环境中,一个节点只能是NameNode或DataNode中的一个,也只能是JobTracker或TaskTracker中的一。
假设现在有三个节点 :一个NameNode,两个DataNode ,主机名分别为namenode,datanode1,datanode2,详细过程如下:记录每个节点的ip,使用命令ifconfig,获取每个节点的ip。
在每个节点上修改/etc/hosts文件:
#假设三个节点的ip分别是192.x.x.1,192..x.x.2,192.x.x.3
#在/etc/hosts文件中添加:
192.x..x.1 namenode
192.x..x.2 datanode1
192.x..x.3 datanode2
在集群每个节点的/etc/hosts文件中添加以上内容,这是一份本地DNS表,记录了集群中每个节点的对应的ip地址和主机名;
接下来,首先在每个节点上生成SSH协议的密钥,如伪分布式模式中那样,在每个节点上ssh localhost成功。
然后,在集群中分发公钥,假设现在是3个节点,需要做的是将节点1的公钥追加到节点2和节点3的hadoopuser用户的~/.ssh/authorized_keys文件中。同样的,节点2将自己的公钥追加到节点1和节点3中,节点3将自己公钥追加到节点1和节点2中,这样,每两个节点之间,都能通过SSH无秘钥登陆,因为在SSH协议中,如果地址为A的主机向地址为B的主机请求通信时,SSH协议会先检查authorizedkeys文件,看本机是否保存有A的公钥,如果有,则允许无密码登录本机或交换数据,否则要求远程主机A验证本机密码;
最后每个节点hadoopuser用户的~/.ssh/authorized_keys文件应该保存了集群中每个节点的密钥;其实可以只需将集群中所有节点的密钥统一发送给节点1,由节点1组合成一个秘钥集合的authorzied_keys文件,再由节点1分发给其他每个节点,每个节点替换、保存~/.ssh/authorized_keys文件就可以了;
分发秘钥的使用的命令如下:
#假设主机ip地址为192.xxx.xxx.xxx 用户名为hadoopuser
ssh-copy-id -i ~/.ssh/id_rsa_pub hadoopuser@192.xxx.xxx.xxx
检查任意一个节点是否可以通过SSH登录到集群中其他任意一台主机上,检查命令如下:
ssh namenode
ssh datanode1
ssh datanode2
如果都能通,则说明SSH配置成功。
步骤四:配置Hadoop配置文件
对于hadoop配置文件的修改添加的属性和伪分布式下类似,但有几个需要注意的地方与伪分布式不同;
1)配置core-site.xml文件
<configuration>
<property>
<name>fs.defalut.name</name>
<value>hdfs://namenode:9000</value>
<description></description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoopuser/hdfs/tmp</value>
<description></description>
</property>
</configuration>
注意将伪分布式模式下fs.default.name项属性的localhost改为集群中的namenode,也就是主节点,其他各属性的值与伪分布式模式下相同。
2)配置hdfs-site.xml文件
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/home/hadoopuser/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoopuser/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
hdfs-site.xml与伪分布式略有不同的是,dfs.name.dir属性只需在namenode上配置,也就是在主节点上配置,但在集群上分发以上相同的文件也不会有问题,如果一个节点不是namenode,也就是说它不是主节点,将不会读取dfs.name.dir属性。
3)配置mapred-site.xml文件
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>namenode:9001</value>
</property>
</configuration>
jobTacker运行在主节点上,所以设置其值为namenode。
另外,集群环境下,每台机器上需要重新配置master和slave文件,文件都在conf目录下面,且配置都一样:
4)配置master文件
#master
#一台主节点
namenode
5)配置slave文件
#slave
#两台从节点
datanode1
datanode2
在实际工程应用中,所有的配置文件可以只需要在主节点NameNode上配置一次,然后可以通过如下命令发给每个从节点DataNode,可以不需要在各个节点上都配置一遍,节省时间和防止每节点单独配置出错。下发命令如下:
#例如将core-site.xml文件发到主机ip为192.xxx.xxx.xx1 用户名为hadoopuser的 #DataNode上,DataNode的hadoop的安装目录为 /home/hadoopuser/hadoop-1.2.1
scp /home/hadoopuser/hadoop-1.2.1/conf/core-site.xml hadoopuser@192.xxx.xxx.xx1:
/home/hadoopuser/hadoop-1.2.1/conf
步骤五:格式化文件系统,启动Hadoop守护进程
在主节点namenode上执行如下命令:
hadoop nomenode -format
start-all.sh
然后可以在各个节点上查看守护进程启动情况:
1)namenode节点
在namenode节点上启动的守护进程应该有:
- Namenode
- SecondarNameNode
- JobTracker
执行jps命令,查看启动的进程:

在浏览器中键入192.x.x.1:50070,可以看到下图
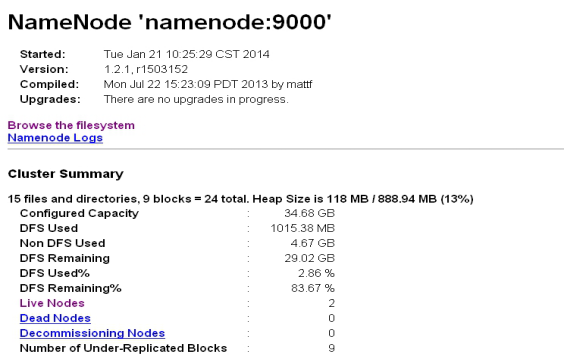
选择Live Nodes,点击进入,如下图所示
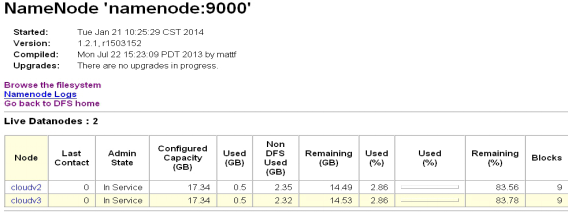
在浏览器中键入192.x.x.1:50030,可以看到下图
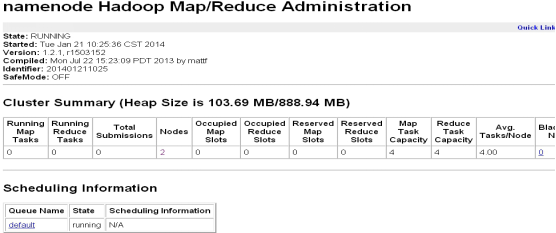
2)datanode节点
在datanode节点上启动的守护进程应该有:
- DataNode
- TaskTracker
执行jps命令,查看启动的进程:
